Two services talk to each other. The first sends a request. The second processes it. This works until the second service is slow, or down, or flooded with requests it cannot finish before the next ones arrive. The first service either waits, or it fails, or it drops data on the floor.
A message queue sits between them. The first service drops a message into the queue and moves on. The second pulls from the queue when it's ready. The two services stop depending on each other's availability. The coupling breaks.
That much is simple. The harder question is which queue to use, because Kafka, RabbitMQ, and SQS make different promises, serve different failure modes, and carry different operational costs. Choosing wrong doesn't break your system immediately. It accumulates as subtle pressure: reprocessing logic that doesn't quite work, ordering guarantees that hold until they don't, a queue that scales in one direction but not the one you needed.
What a Message Queue Actually Does
Before comparing tools, the mechanics matter.
A producer writes a message to the queue. A consumer reads it. The queue holds the message until the consumer acknowledges receipt. If the consumer crashes mid-processing, the queue redelivers. This at-least-once delivery guarantee is the foundation of every system described below.
"At-least-once" means what it says: messages arrive at least once, possibly more. If a consumer crashes after processing but before acknowledging, the queue assumes failure and redelivers. Your consumer sees the message twice. This is the normal case. Any queue-based system needs idempotent consumers: processing the same message twice should produce the same result as processing it once.
Some queues also offer at-most-once delivery: send the message once, never redeliver. You lose durability. You gain simplicity. A few offer exactly-once delivery. The guarantees are real but come with coordination overhead and don't survive every failure scenario. Most production systems run at-least-once with idempotent consumers.
Kafka
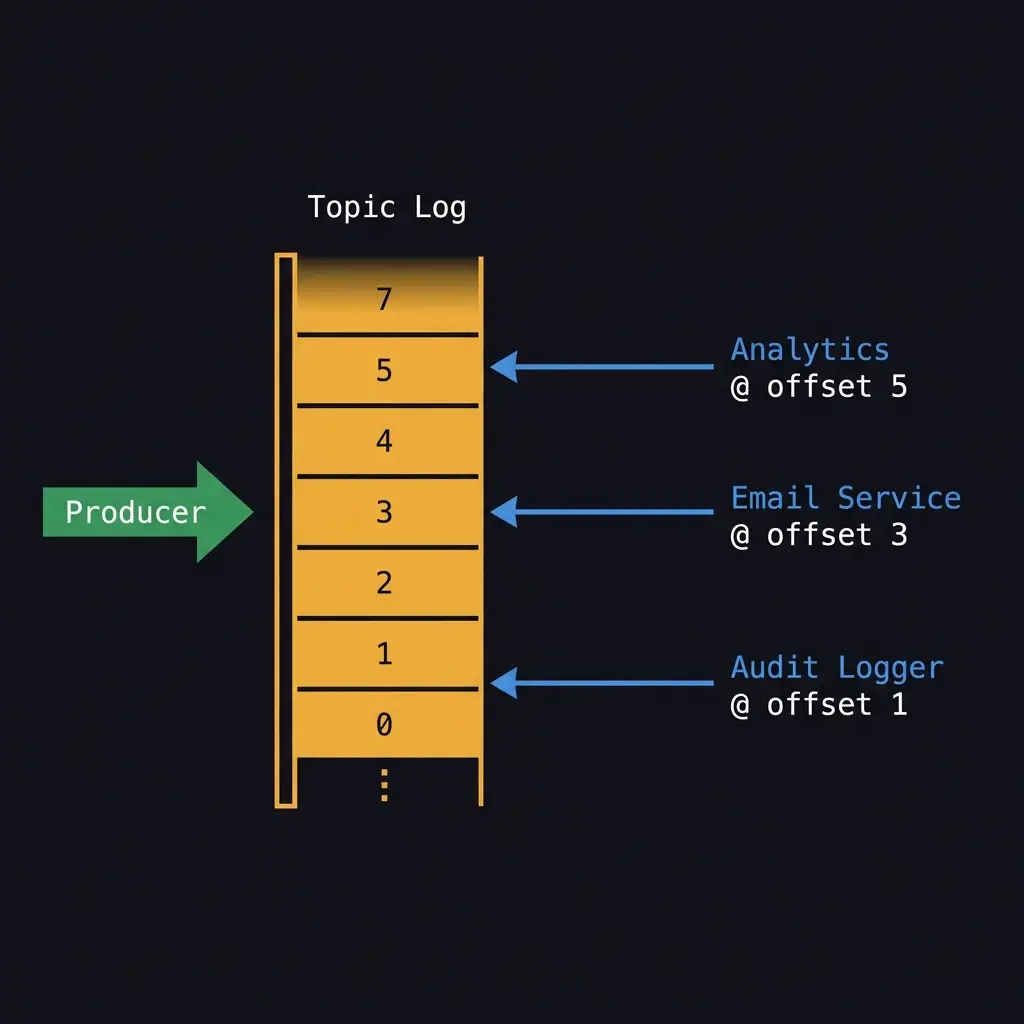
Kafka stores messages as an ordered, append-only log. Producers write to a topic. Consumers read from an offset in that log. The message is not deleted after reading. It stays until a retention period expires, which you configure. A week is common. A day is common for high-volume topics. Indefinite retention is possible at cost.
This changes what a queue can do. Multiple independent consumers can read the same message by maintaining their own offsets. An analytics pipeline and an email service and an audit logger can all consume the same order-created event without any coordination between them. Each reads at its own pace.
Kafka also orders messages within a partition. If ordering matters, you route messages with the same key to the same partition. All events for a given user ID arrive in order. All events for a given account arrive in order. Ordering across partitions doesn't hold. Most systems don't need it to.
The log is also a time machine. If your consumer had a bug last Tuesday and processed three hours of events incorrectly, you reset its offset to Tuesday and replay. The messages are still there. You reprocess, fix the bad state, move on. This is not a feature you plan to use. It's a feature you're glad you have when you need it.
The operational cost of Kafka is real. You need brokers, you need ZooKeeper (or KRaft in modern versions), you need to plan partitions and replication factors upfront. Partition counts affect parallelism and can't be reduced after the fact. Adding partitions is possible but changes key-based routing. Kafka is not what you reach for when you need a queue in an afternoon.
Use Kafka when:
- You have multiple independent consumers reading the same events (fan-out without duplication)
- Ordering within a key matters
- Replay and event sourcing are part of your architecture
- You're moving high volume: thousands to millions of messages per second
- You want an event log as the system of record
Skip Kafka when:
- You're routing work to one consumer and don't need replay
- Your team doesn't have the operational capacity to run it
- The schema of your messages changes frequently and you haven't invested in a schema registry
- You need per-message routing logic or complex dead-letter handling
RabbitMQ
RabbitMQ is a broker. Producers send messages to an exchange. The exchange routes messages to queues based on routing rules. Consumers pull from queues. When a consumer acknowledges a message, the broker deletes it.
The routing is where RabbitMQ earns its place. You can route by exact key (direct exchange), by pattern match (topic exchange), or fan out to every bound queue (fanout exchange). A single message can land in multiple queues with no coordination from the producer. You can build complex routing topologies: priority queues, delayed queues, dead-letter exchanges that catch failed messages and route them elsewhere for inspection.
RabbitMQ was built for task queues. A web server receives a request that kicks off a long job: image processing, PDF generation, sending an email. The server drops a message into the queue. Workers pull from the queue and run the job. When the job finishes, the worker acknowledges and the message is gone. That's the pattern RabbitMQ handles cleanly.
Message persistence works differently than Kafka. RabbitMQ can persist messages to disk, but the model is not a log. Once a message is consumed and acknowledged, it's deleted. You cannot replay. A consumer that died processing a batch can recover the unacknowledged messages, but you cannot go back to yesterday's messages and reread them.
Push delivery is another distinction. RabbitMQ pushes messages to connected consumers rather than waiting for them to pull. This means a fast producer can overwhelm a slow consumer. Consumer prefetch limits control how many unacknowledged messages a consumer holds at once. Setting this correctly matters more than most documentation suggests.
Use RabbitMQ when:
- You need complex routing logic between producers and consumers
- Work queue semantics are the core pattern: one job, one worker, delete on completion
- You need priority queues or delayed message delivery
- Your team is comfortable with a well-documented, operationally mature broker
- You want per-message TTL or dead-letter handling out of the box
Skip RabbitMQ when:
- You need replay
- You have many independent consumers needing the same events without coordination
- Your message volume is extreme (millions per second; RabbitMQ handles this with tuning, but Kafka is easier to scale to this range)
Amazon SQS
SQS is a managed queue. There are no brokers to run, no partitions to plan, no replication factors to set. You create a queue, write messages to it, and poll for them. The operational overhead is near zero.
Messages in SQS are not ordered by default. Standard queues offer best-effort ordering with at-least-once delivery. FIFO queues add strict ordering and exactly-once processing within a message group, at the cost of lower throughput and higher price. Standard queues scale to essentially unlimited throughput. FIFO queues cap at 3,000 messages per second with batching.
The visibility timeout model is how SQS handles in-progress messages. When a consumer receives a message, it becomes invisible to other consumers for a configurable duration. If the consumer acknowledges before the timeout, the message is deleted. If it doesn't, the message becomes visible again and another consumer picks it up. This is a pull-based at-least-once delivery model with no coordination between consumers.
SQS integrates directly with the AWS ecosystem. Lambda functions trigger on SQS messages. SNS fans out to multiple SQS queues. EventBridge routes events into queues. If your infrastructure runs on AWS, the integration cost is low and the failure modes are well understood.
Dead-letter queues are simple to configure. After a message fails a set number of receive attempts, SQS moves it to a configured DLQ. You inspect it, fix the consumer, and reprocess. The pattern is clear and doesn't require custom tooling.
The tradeoffs: you can't replay consumed messages. You can't maintain multiple independent consumer groups reading the same message stream without routing that stream through SNS to multiple queues first. Ordering in standard queues is not guaranteed. Long polling helps reduce empty receives but the polling model adds latency compared to push-based brokers.
Use SQS when:
- You're on AWS and want zero queue infrastructure to run
- Work queue semantics fit: one message, one consumer, delete on acknowledgment
- Throughput requirements are high but replay and fan-out aren't needed
- You want native integration with Lambda, SNS, and EventBridge
- Your team shouldn't be running distributed systems infrastructure
Skip SQS when:
- You need guaranteed ordering across a large message stream (FIFO has real throughput limits)
- Multiple independent consumers need to read the same event stream
- You need replay
- You're not on AWS, or the egress costs matter
The Decision

Three questions settle most choices.
Do you need multiple independent consumers reading the same events? Kafka. Fan-out through SNS-to-SQS is possible but adds operational complexity and doesn't scale as cleanly as Kafka's consumer group model.
Do you need replay? Kafka. Neither RabbitMQ nor SQS retains messages after consumption. If your architecture benefits from replaying events (event sourcing, recovering from consumer bugs, backfilling new services with historical data), Kafka is the only option here.
Is your team on AWS and does the message pattern fit "work queue"? SQS. Zero infrastructure, clean AWS integration, proven at scale. Add an SNS topic in front if you need fan-out to multiple queues.
RabbitMQ wins when you need routing logic that neither Kafka nor SQS provides cleanly. Priority queues, pattern-based routing, complex exchange topologies. It also wins when your team knows it well and the volume doesn't push into Kafka territory.
The Delivery Assumption That Will Burn You
Every queue delivers messages at least once. Every consumer needs to handle duplicates. This is not a footnote. On any reasonably trafficked system, duplicates are routine. The consumer acknowledges after writing to a database, but crashes before the ack reaches the broker. The message redelivers. The database write runs again.
If your database write is idempotent by design, nothing breaks. If it isn't, you get duplicate records, double-charged users, or orders processed twice.
Idempotency keys, upsert semantics, deduplication tables: whichever approach fits your data model, the implementation belongs in the consumer, not in hopes that the queue will handle it. No queue guarantees the world only delivers anything once. Design for the second delivery being normal. It is.
A Note on Managed Kafka
If Kafka fits your needs but the operational cost is a concern, managed options exist. Confluent Cloud, Amazon MSK, and Aiven Kafka run the brokers and handle upgrades. You pay more per message than self-hosted but less in engineering time. For teams that need Kafka semantics without a dedicated platform team, the tradeoff is usually straightforward: you keep the consumer group model and replay capability, and lose the 2am broker pages.
The semantic guarantees, the consumer group model, the replay capability: they are the same. The difference is who wakes up at 2am when a broker fails.